


What do we have?
dev.family is an outsourced developer specializing in e-comm and food tech, making cross-platform mobile and web.

We have about 10 projects in development simultaneously, plus there are old ones that we support. When we conceived all this “flipping” described in the article, we wanted to ensure that after each commit to the master branch, it would automatically expand. So that, if desired, you can independently deploy other branches, and deploy to production. In our new picture of the world, we did not have to suffer due to the presence of different versions of the software, HTTP could be issued automatically, and old and unnecessary branches would be deleted over time. And all this so that we can focus on development and not waste time deploying each project to the test site.
Like many, a long time ago we deployed everything by hand. We went to the server, git pull, and executed the migration commands. Then they remembered that during the migration they forgot to execute some command, something broke and off they went.
And in the process, it was possible to lie down while the site was being updated, since, for example, the code could already be updated, but the migration in the database could not. And God forbid if we have dev, stage, prod! Go to each one, and turn it around with your hands. But somehow we wanted to expand several branches in parallel and also had to manually ... It's a nightmare, it's scary to remember, but the nostalgia is pleasant.
Over time, many problems arise:
automatic issuance of certificates;
scaling;
high availability;
ease of container management.
Kubernetes provided an out-of-the-box solution for these tasks and allowed us to quickly and efficiently solve the corresponding problems.

For CI/CD, we used GitLab Runner, since we store projects in our own GitLab Instance. Kubernetes was raised via microk8s.
The deployment took place using a helm. This decision lasted a long time, but gave rise to many problems:
For reliable operation of a Kubernetes cluster, a minimum of 3 nodes is required, we only had one.
The rapid development of Kubernetes and the difficulties associated with updating it.
Huge yaml that is hard to read, create and maintain.
It takes a lot of time to learn and solve all sorts of problems. We do not have a dedicated DevOps team.
In the process, we found out that Kubernetes is not suitable for all our tasks and needs. Its support required a lot of additional effort and time, as well as a significant amount of computing resources. We abandoned it in production and continued to look for optimal solutions for each of our projects.
However, the experience of using Kubernetes was very useful, and we always keep in mind that when the load on the application increases, we can turn to this tool.
What did we end up with?
Tired of dealing with the constant problems and complexity of Kubernetes, they began to look for an alternative. Swarm and other solutions were considered, but nothing better than Docker Compose was found. We stopped on it.
Why? Because every developer in the company knows how to work with Docker Compose. It's hard to shoot yourself in the foot with it, it's easy to maintain and deploy. And its disadvantages are practically not noticeable on our projects.
The cons I consider:
Scaling: Docker Compose does not have built-in tools for scaling applications.
Resource Limiting: Docker Compose does not provide the ability to limit resource consumption within a single container.
No updates without downtime. When updating an application in Docker Compose, it becomes unavailable for a couple of seconds.
Then we began to look for a solution for deploying to the dev environment. The main thing we needed was that each branch be available at its own address and receive a certificate for https.
It was not possible to find a ready-made solution, so we implemented our own deployer.
What did we come up with for deployment?
The diagram of our deployer looks like this:
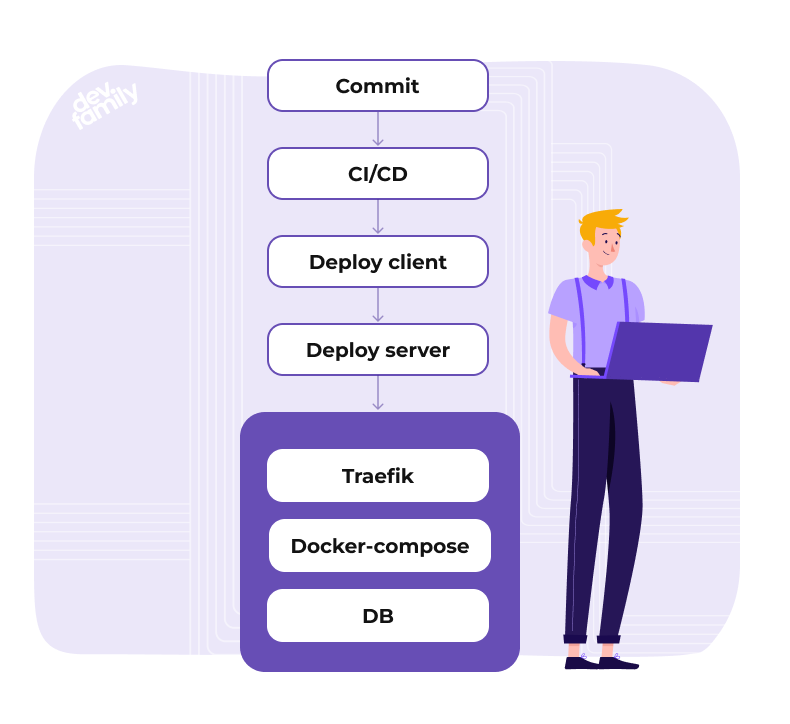
Deploy client and deploy server are two binaries written in golang. The client is packaged in docker and placed in the registry of our GitLab.
All the client does is take all the files from the directory and send them to the deploy server via http. Along with the files, it also sends GitLab variables. In CI/CD it looks like this:
review:
image: gitlab/company/ci-deployer/client:latest
stage: review
script:
- deploy
//other code
function deploy() {
mv ci/dev /deploys;
/golang/main up;
}
Deploy server is running as a daemon and accepts files via http. The basic file structure looks like this:
config.json
Contains the configuration. Example:
{
"not_delete_old" : false, //projects that have not been pushed for 28 days are deleted
"cron": {
"enable": true, //setting cron commands
"commands": [
{
"schedule": "* * * * *",
"task": "cron" //task from Taskfile.yml will be executed
}
]
}
}
Taskfile.yml
Contains tasks that will be executed during deployment. The utility is installed on the system.
version: '3'
tasks:
up:
cmds:
- docker-compose pull
- docker-compose up -d --remove-orphans
- docker-compose exec -T back php artisan migrate --force
- docker-compose exec -T back php artisan search:index
down:
cmds:
- docker-compose down
cron:
cmds:
- docker-compose exec -T back php artisan schedule:run
tinker:
cmds:
- docker-compose exec back php artisan tinker
.env
Environment variables for docker Compose.
COMPOSE_PROJECT_NAME={{ .BaseName }}
VERSION={{ .Version }}
REGISTRY={{ .RegImage }}
docker-compose.yaml
version: "3.8"
services:
front:
networks:
- traefik
restart: always
image: ${REGISTRY}/front:${VERSION}
env_file: .env.fronted
labels:
- "traefik.enable=true"
- "traefik.http.routers.{{ .BaseName }}.rule=Host(`vendor.{{ .HOST }}`)"
- "traefik.http.routers.{{ .BaseName }}.entrypoints=websecure"
- "traefik.http.routers.{{ .BaseName }}.tls.certresolver=myresolver"
- "traefik.http.routers.{{ .BaseName }}.service={{ .BaseName }}"
- "traefik.http.services.{{ .BaseName }}.loadbalancer.server.port=3000"
networks:
traefik:
name: app_traefik
external: true
After accepting the files, the server starts its work. Based on the GitLab variables, which include the name of the branch, project, etc., variables for deployment are created. BaseName is created like this
return fmt.Sprintf("%s_%s_%s",
receiver.EnvGit["CI_PROJECT_NAMESPACE"], //project group
receiver.EnvGit["CI_PROJECT_NAME"], //project name
receiver.EnvGit["CI_COMMIT_BRANCH"], //branch name
)
All files are treated as golang templates. Therefore, for example, in docker-compose.yaml, instead of {{ .BaseName }} , the generated unique name for deployment will be substituted. {{ .HOST }} is also built based on the branch name.
Next, a database is created for the branch if it has not been created. If the branch is different from the main, then the database is not created from scratch, but the main database is cloned. This is handy, as branch migrations don't affect main. But the data from main in the branch can be useful.
After that, ready-made files are placed in the directory, along the path
/project group/project name/branch name
And the command is executed in the task-up system, which is described in the Taskfile.yml file. It already describes commands for a specific project.
After that, the deployment becomes available on the traefik network, which automatically starts proxying traffic to it and issues a let's encrypt certificate.
What do we end up with?
This approach greatly simplified development: it became easier to use various new utilities that can be easily added as another service in docker-compose.yaml. And now every developer understands how the test environment works.
This system is easy to customize specifically to our needs. For example, we needed to add the ability to run cron. The solution is very simple. We create a configuration through config.json, parse it into a golang structure, and run cron inside the server, which can be dynamically changed.
Another idea was implemented: turn off inactive projects that have not been pushed for more than 28 days. To do this, we created a file with data on the last deployment.
"XXX_NAME": {
"user": "xxxx",
"slug": "xxxx",
"db": "xxx",
"branch": "main",
"db_default": "xxxxx",
"last_up": "2023-04-07T09:06:15.017236822Z",
"version": "cb2dd08b02fd29d57599d2ac14c4c26200e3c827",
"dir": "/projects/xxx/backend/main",
},
Further, the cron inside the server deployer once a day checks this file, if it sees an inactive project in it, goes to dir and executes the down command. Well, it deletes the database if it is not the main branch. And for informational content, the server, after the work is done, gives the logs to the client, which displays them in GitLab.
It looks like this when everything is fine
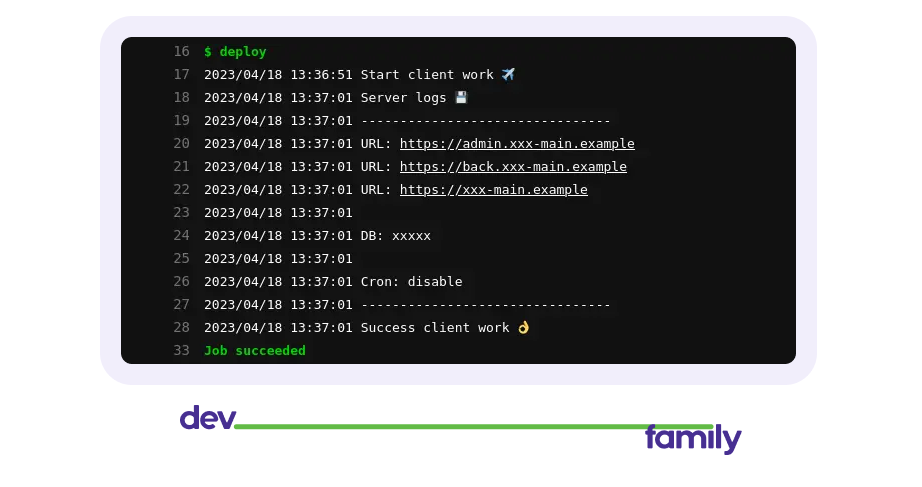
ххх - project name
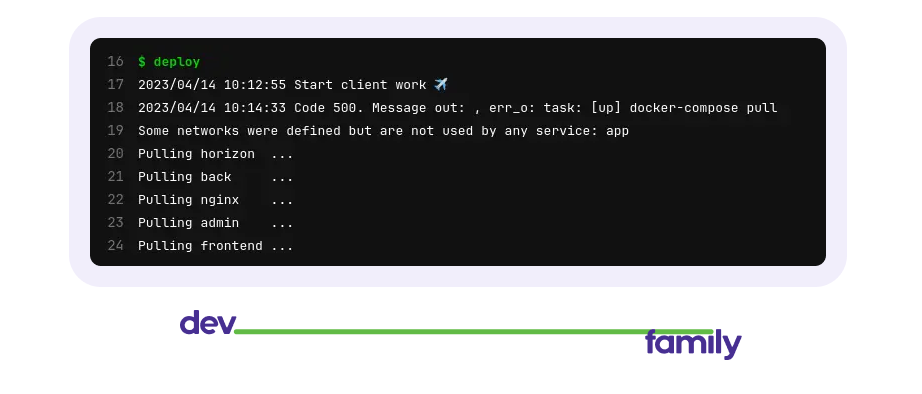
Well, or so, when something went wrong :)
It would be cool if you share your experience in the comments.
